Azure Data Platform - Data Ingest Design Patterns
As technology has matured over the years and the growth of hyper-compute cloud platforms have reduced the cost and expense of building elastic and scale-n data platforms, the design patterns have veered towards reducing complexity for enterprise data architectures. The patterns addressed here move to fewer, more versatile components and services, rather than narrow-focus systems that add complexity, additional system administration and specialized developer and engineer skillsets that are needed to hold the platform together. There are other opensource solutions as well in azure such as HDInsight\HDP Spark, HDInsight\HDP Storm and Azure Databricks. The decision to use one technology verses another comes down to cost, administration and required skillsets of existing staff.
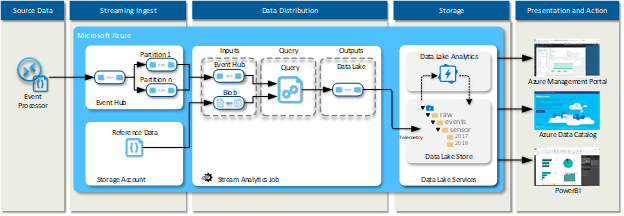
The component model/data-flow diagram below shows that various components that can be leveraged in the Azure cloud platform.
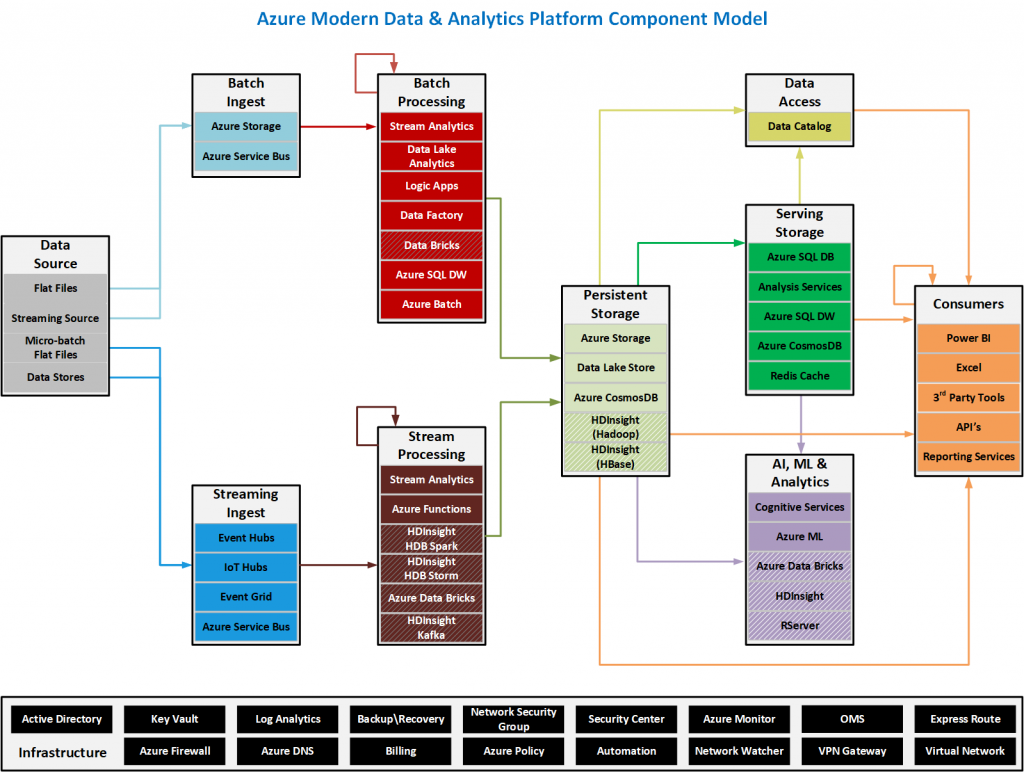
There are three primary design patterns that are presented:
- Batch/micro-batch streaming data ingest
- Near real-time streaming data ingest
- Near real-time streaming data ingest – hot path
Batch/Micro-batch Streaming Data Ingest
The micro-batch data ingest pattern is similar to the near real-time data ingest pattern. The intent is to package the data in small consumable datasets that can be ingested with minimal disruption to the data flow instead of sending a single tuple at a time.
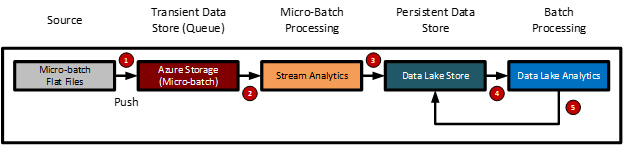
The batch/micro-batch streaming data ingest pattern workflow is as follows:
- External data provider creates a batch of data that is pushed to a transient data store (Azure Storage) or queue for processing
- A streaming data processing engine (Azure Stream Analytics) receives the file
- The data is passed on to the persistent data store (Azure Data Lake)
- Post processing (de-duplication) occurs on the recently arrived data (Data Lake Analytics)
- Data is published back to the data lake store (Azure Data Lake Store)
- The diagram below shows the logical model for the batch/micro batch streaming data ingest pattern.
The diagram below shows the logical model for the batch/micro batch streaming data ingest pattern.
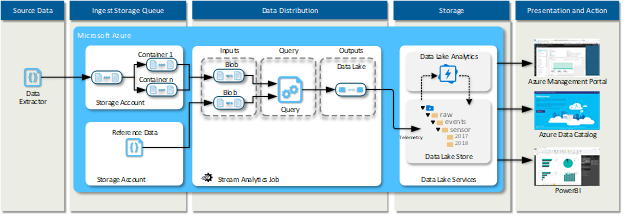
Near Real-time Streaming Data Ingest
This pattern is for working with an infinite stream of data that is pushed a record at a time. Another common term associated with this pattern is event sourcing.
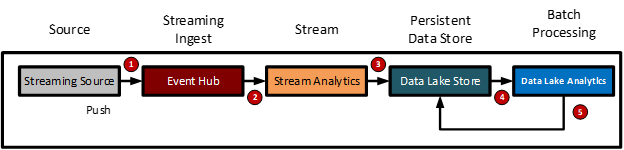
The near real-time streaming data ingest pattern logical workflow is as follows:
- External data provider (event processing host) pushes a tuple of data to a steaming transient data store (Azure Event Hub, IoT Hub or EventGrid) or queue for processing
- A streaming data processing engine (Azure Stream Analytics) receives the tuple of data
- The data is passed on to the persistent data store (Azure Data Lake)
- Post processing occurs on the recently arrived data (Data Lake Analytics)
- Data is published back to the data lake store (Azure Data Lake Store)
The diagram below shows the logical model for the near real-time streaming data ingest pattern.
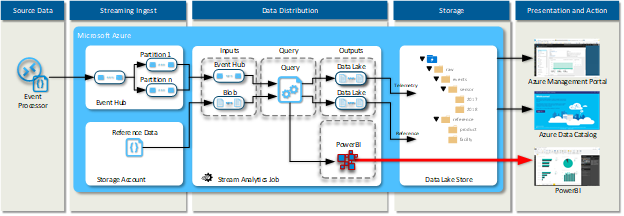
Near Real-time Streaming Data Ingest – Hot Path
This pattern is for working with an infinite stream of data that is pushed a record at a time and needs to be viewed or processed as it is received.
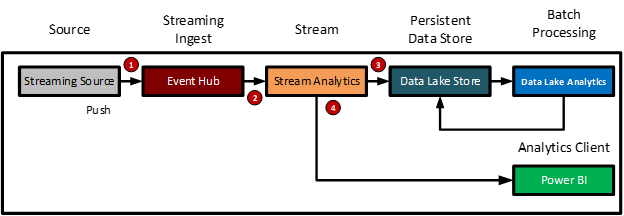
The near real-time streaming data ingest -hot path pattern logical workflow is as follows:
- External data provider (event processing host) pushes a tuple of data to a steaming transient data store (Azure Event Hub or IoT Hub) or queue for processing
- A streaming data processing engine (Azure Stream Analytics) receives the tuple of data
- The data is passed it on to the persistent data store (Azure Data Lake)
- The data is passed it on to the streaming data source for the analytic client (PowerBI)
The diagram below shows the logical model for the near real-time streaming data -hot path ingest pattern.